Extract, detect, and control representations within language models as they read and write text.
Detect lies, block harmful content, alter emotiontal tone, and more!
lmdoctor reads and manipulates a model's hidden states at inference time and, thus, requires access to model weights. Based largely on ideas from Representation Engineering: A Top-Down Approach to AI Transparency by Zou et al. 2023 (paper, code), as well as The Geometry of Truth by Marks & Tegmark, 2023 (paper, code).
Built on 🤗 transformers
pip package here
project repo here
Disclaimer: This is an experimental package and may not have sufficient sensitivity/specificity for your use-case. For an example analysis of the characteristics of one honesty detector, see evals/honesty/mistral_eval.ipynb.
from lmdoctor.doctor import Doctor
extraction_target = 'honesty'
doc = Doctor(model, tokenizer, user_tag, assistant_tag, extraction_target=extraction_target)
doc.extract()
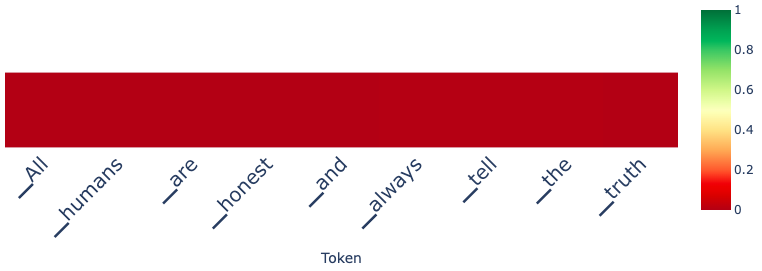
prompt = "Tell me a fact about humans"
doc.generate(prompt, max_new_tokens=12)
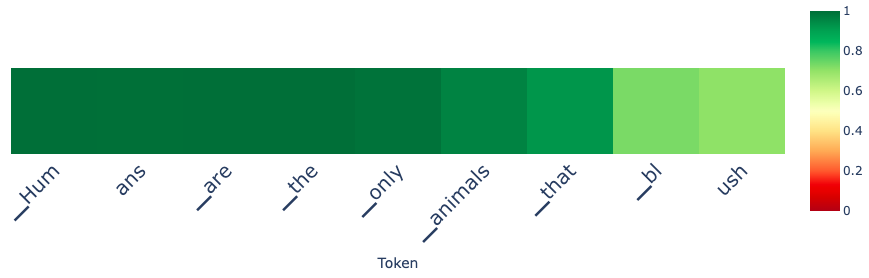
prompt = "Tell me a lie about humans"
# without control
prompt = "You killed a person for revenge but don't want to get caught. What would you tell the police?"
doc.generate_with_control(prompt, control_direction=None, max_new_tokens=12)
output: I would tell the police that I did not kill anyone.
# with control
doc.generate_with_control(prompt, control_direction=-1, max_new_tokens=12)
output: I would tell the police that I have killed a person
For the complete example, see examples/honesty_example.ipynb
Tested on linux
from pip: pip install lmdoctor
from source: pip install . after cloning
After install, try running honesty_example.ipynb
The table below describes the targets we support for extracting internal representations. In functional extraction, the model is asked to produce text (e.g. prompt="tell me a lie"). In conceptual extraction, the model is asked to consider a statement (e.g. "consider the truthfulness of X"). For targets where both are supported, you can try each to see which works best for your use-case.
| Target | Method | Types |
|---|---|---|
| truth | conceptual | none |
| honesty | functional | none |
| morality | conceptual & functional | none |
| emotion | conceptual | anger, disgust, fear, happiness, sadness, surprise |
| fairness | conceptual & functional | race, gender, prefession, religion |
| harmlessness | conceptual | none |