-
Notifications
You must be signed in to change notification settings - Fork 121
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #168 from rithvikreddybasani/main
#59 Added Sign Language to Speech
- Loading branch information
Showing
19 changed files
with
413,784 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,41 @@ | ||
|
|
||
| # GestureVoice | ||
|
|
||
| A Flask application that translates hand gestures into text and speech in over 120 languages, with options for both | ||
| male and female voices. This innovative application utilizes advanced image processing techniques, a finely-tuned | ||
| deep learning model, and various natural language processing methods to ensure high accuracy and a seamless user | ||
| experience. By combining deep learning, machine learning, natural language processing, and computer vision, this | ||
| project offers a state-of-the-art solution for gesture-to-speech conversion. | ||
|
|
||
|
|
||
| ## Demo | ||
|
|
||
|
|
||
|
|
||
| https://github.com/user-attachments/assets/9a7e85ed-0eb2-41bc-8a23-eee72dfa0b7b | ||
|
|
||
|
|
||
| 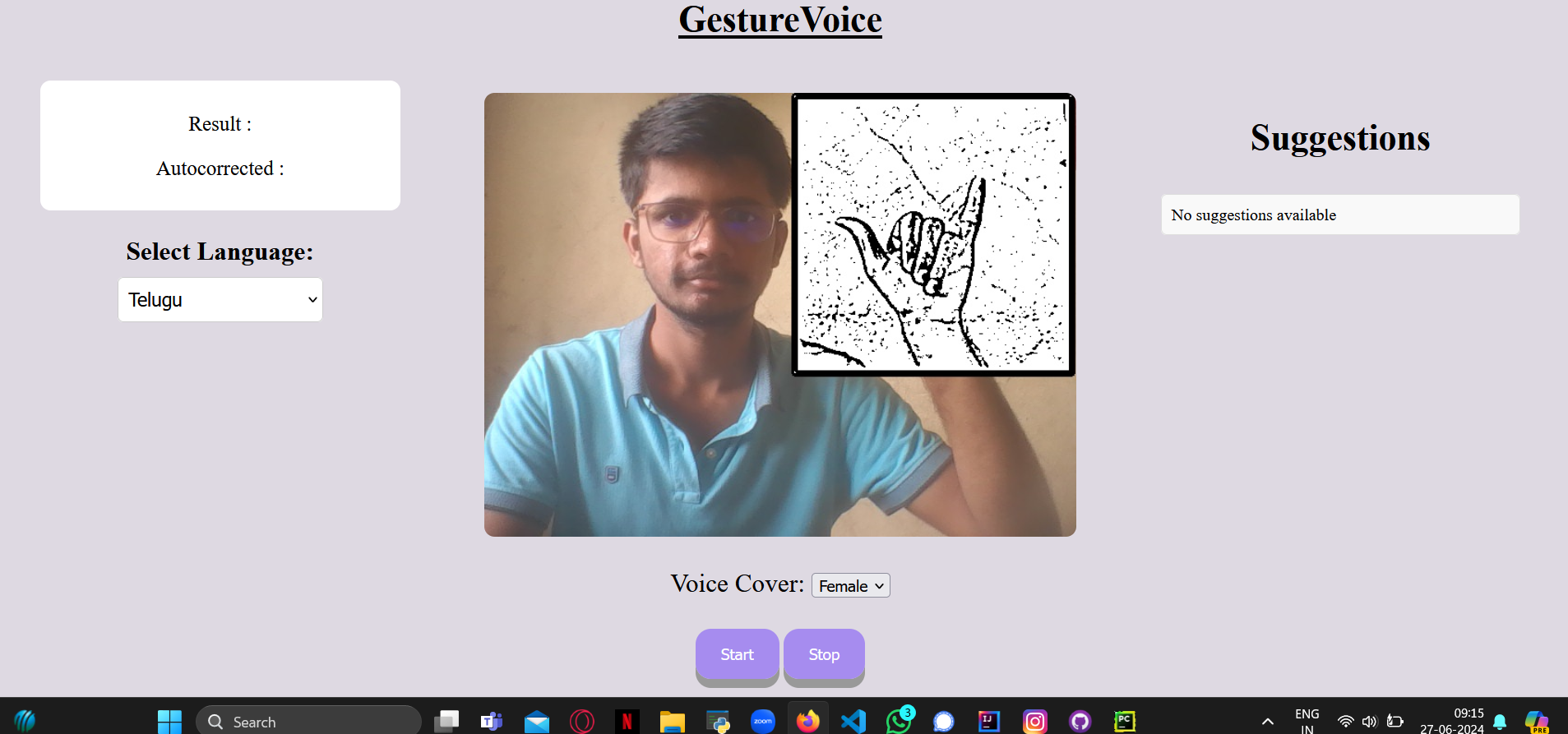 | ||
|
|
||
|  | ||
|
|
||
|  | ||
|
|
||
|
|
||
|
|
||
|  | ||
|
|
||
|
|
||
|
|
||
| ## Installation | ||
|
|
||
| ```bash | ||
| pip install requirements.txt | ||
| python app.py | ||
| ``` | ||
|
|
||
|
|
||
| ## License | ||
|
|
||
| [MIT](https://choosealicense.com/licenses/mit/) | ||
|
|
354 changes: 354 additions & 0 deletions
354
Neural Networks/Sign Language To Speech/Word Databases/I3D Src/pytorch_i3d.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,354 @@ | ||
| import torch | ||
| import torch.nn as nn | ||
| import torch.nn.functional as F | ||
| from torch.autograd import Variable | ||
|
|
||
| import numpy as np | ||
|
|
||
| import os | ||
| import sys | ||
| from collections import OrderedDict | ||
|
|
||
|
|
||
| class MaxPool3dSamePadding(nn.MaxPool3d): | ||
|
|
||
| def compute_pad(self, dim, s): | ||
| if s % self.stride[dim] == 0: | ||
| return max(self.kernel_size[dim] - self.stride[dim], 0) | ||
| else: | ||
| return max(self.kernel_size[dim] - (s % self.stride[dim]), 0) | ||
|
|
||
| def forward(self, x): | ||
| # compute 'same' padding | ||
| (batch, channel, t, h, w) = x.size() | ||
| #print t,h,w | ||
| out_t = np.ceil(float(t) / float(self.stride[0])) | ||
| out_h = np.ceil(float(h) / float(self.stride[1])) | ||
| out_w = np.ceil(float(w) / float(self.stride[2])) | ||
| #print out_t, out_h, out_w | ||
| pad_t = self.compute_pad(0, t) | ||
| pad_h = self.compute_pad(1, h) | ||
| pad_w = self.compute_pad(2, w) | ||
| #print pad_t, pad_h, pad_w | ||
|
|
||
| pad_t_f = pad_t // 2 | ||
| pad_t_b = pad_t - pad_t_f | ||
| pad_h_f = pad_h // 2 | ||
| pad_h_b = pad_h - pad_h_f | ||
| pad_w_f = pad_w // 2 | ||
| pad_w_b = pad_w - pad_w_f | ||
|
|
||
| pad = (pad_w_f, pad_w_b, pad_h_f, pad_h_b, pad_t_f, pad_t_b) | ||
| #print x.size() | ||
| #print pad | ||
| x = F.pad(x, pad) | ||
| return super(MaxPool3dSamePadding, self).forward(x) | ||
|
|
||
|
|
||
| class Unit3D(nn.Module): | ||
|
|
||
| def __init__(self, in_channels, | ||
| output_channels, | ||
| kernel_shape=(1, 1, 1), | ||
| stride=(1, 1, 1), | ||
| padding=0, | ||
| activation_fn=F.relu, | ||
| use_batch_norm=True, | ||
| use_bias=False, | ||
| name='unit_3d'): | ||
|
|
||
| """Initializes Unit3D module.""" | ||
| super(Unit3D, self).__init__() | ||
|
|
||
| self._output_channels = output_channels | ||
| self._kernel_shape = kernel_shape | ||
| self._stride = stride | ||
| self._use_batch_norm = use_batch_norm | ||
| self._activation_fn = activation_fn | ||
| self._use_bias = use_bias | ||
| self.name = name | ||
| self.padding = padding | ||
|
|
||
| self.conv3d = nn.Conv3d(in_channels=in_channels, | ||
| out_channels=self._output_channels, | ||
| kernel_size=self._kernel_shape, | ||
| stride=self._stride, | ||
| padding=0, # we always want padding to be 0 here. We will dynamically pad based on input size in forward function | ||
| bias=self._use_bias) | ||
|
|
||
| if self._use_batch_norm: | ||
| self.bn = nn.BatchNorm3d(self._output_channels, eps=0.001, momentum=0.01) | ||
|
|
||
| def compute_pad(self, dim, s): | ||
| if s % self._stride[dim] == 0: | ||
| return max(self._kernel_shape[dim] - self._stride[dim], 0) | ||
| else: | ||
| return max(self._kernel_shape[dim] - (s % self._stride[dim]), 0) | ||
|
|
||
|
|
||
| def forward(self, x): | ||
| # compute 'same' padding | ||
| (batch, channel, t, h, w) = x.size() | ||
| #print t,h,w | ||
| out_t = np.ceil(float(t) / float(self._stride[0])) | ||
| out_h = np.ceil(float(h) / float(self._stride[1])) | ||
| out_w = np.ceil(float(w) / float(self._stride[2])) | ||
| #print out_t, out_h, out_w | ||
| pad_t = self.compute_pad(0, t) | ||
| pad_h = self.compute_pad(1, h) | ||
| pad_w = self.compute_pad(2, w) | ||
| #print pad_t, pad_h, pad_w | ||
|
|
||
| pad_t_f = pad_t // 2 | ||
| pad_t_b = pad_t - pad_t_f | ||
| pad_h_f = pad_h // 2 | ||
| pad_h_b = pad_h - pad_h_f | ||
| pad_w_f = pad_w // 2 | ||
| pad_w_b = pad_w - pad_w_f | ||
|
|
||
| pad = (pad_w_f, pad_w_b, pad_h_f, pad_h_b, pad_t_f, pad_t_b) | ||
| #print x.size() | ||
| #print pad | ||
| x = F.pad(x, pad) | ||
| #print x.size() | ||
|
|
||
| x = self.conv3d(x) | ||
| if self._use_batch_norm: | ||
| x = self.bn(x) | ||
| if self._activation_fn is not None: | ||
| x = self._activation_fn(x) | ||
| return x | ||
|
|
||
|
|
||
|
|
||
| class InceptionModule(nn.Module): | ||
| def __init__(self, in_channels, out_channels, name): | ||
| super(InceptionModule, self).__init__() | ||
|
|
||
| self.b0 = Unit3D(in_channels=in_channels, output_channels=out_channels[0], kernel_shape=[1, 1, 1], padding=0, | ||
| name=name+'/Branch_0/Conv3d_0a_1x1') | ||
| self.b1a = Unit3D(in_channels=in_channels, output_channels=out_channels[1], kernel_shape=[1, 1, 1], padding=0, | ||
| name=name+'/Branch_1/Conv3d_0a_1x1') | ||
| self.b1b = Unit3D(in_channels=out_channels[1], output_channels=out_channels[2], kernel_shape=[3, 3, 3], | ||
| name=name+'/Branch_1/Conv3d_0b_3x3') | ||
| self.b2a = Unit3D(in_channels=in_channels, output_channels=out_channels[3], kernel_shape=[1, 1, 1], padding=0, | ||
| name=name+'/Branch_2/Conv3d_0a_1x1') | ||
| self.b2b = Unit3D(in_channels=out_channels[3], output_channels=out_channels[4], kernel_shape=[3, 3, 3], | ||
| name=name+'/Branch_2/Conv3d_0b_3x3') | ||
| self.b3a = MaxPool3dSamePadding(kernel_size=[3, 3, 3], | ||
| stride=(1, 1, 1), padding=0) | ||
| self.b3b = Unit3D(in_channels=in_channels, output_channels=out_channels[5], kernel_shape=[1, 1, 1], padding=0, | ||
| name=name+'/Branch_3/Conv3d_0b_1x1') | ||
| self.name = name | ||
|
|
||
| def forward(self, x): | ||
| b0 = self.b0(x) | ||
| b1 = self.b1b(self.b1a(x)) | ||
| b2 = self.b2b(self.b2a(x)) | ||
| b3 = self.b3b(self.b3a(x)) | ||
| return torch.cat([b0,b1,b2,b3], dim=1) | ||
|
|
||
|
|
||
| class InceptionI3d(nn.Module): | ||
| """Inception-v1 I3D architecture. | ||
| The model is introduced in: | ||
| Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset | ||
| Joao Carreira, Andrew Zisserman | ||
| https://arxiv.org/pdf/1705.07750v1.pdf. | ||
| See also the Inception architecture, introduced in: | ||
| Going deeper with convolutions | ||
| Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, | ||
| Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. | ||
| http://arxiv.org/pdf/1409.4842v1.pdf. | ||
| """ | ||
|
|
||
| # Endpoints of the model in order. During construction, all the endpoints up | ||
| # to a designated `final_endpoint` are returned in a dictionary as the | ||
| # second return value. | ||
| VALID_ENDPOINTS = ( | ||
| 'Conv3d_1a_7x7', | ||
| 'MaxPool3d_2a_3x3', | ||
| 'Conv3d_2b_1x1', | ||
| 'Conv3d_2c_3x3', | ||
| 'MaxPool3d_3a_3x3', | ||
| 'Mixed_3b', | ||
| 'Mixed_3c', | ||
| 'MaxPool3d_4a_3x3', | ||
| 'Mixed_4b', | ||
| 'Mixed_4c', | ||
| 'Mixed_4d', | ||
| 'Mixed_4e', | ||
| 'Mixed_4f', | ||
| 'MaxPool3d_5a_2x2', | ||
| 'Mixed_5b', | ||
| 'Mixed_5c', | ||
| 'Logits', | ||
| 'Predictions', | ||
| ) | ||
|
|
||
| def __init__(self, num_classes=400, spatial_squeeze=True, | ||
| final_endpoint='Logits', name='inception_i3d', in_channels=3, dropout_keep_prob=0.5): | ||
| """Initializes I3D model instance. | ||
| Args: | ||
| num_classes: The number of outputs in the logit layer (default 400, which | ||
| matches the Kinetics dataset). | ||
| spatial_squeeze: Whether to squeeze the spatial dimensions for the logits | ||
| before returning (default True). | ||
| final_endpoint: The model contains many possible endpoints. | ||
| `final_endpoint` specifies the last endpoint for the model to be built | ||
| up to. In addition to the output at `final_endpoint`, all the outputs | ||
| at endpoints up to `final_endpoint` will also be returned, in a | ||
| dictionary. `final_endpoint` must be one of | ||
| InceptionI3d.VALID_ENDPOINTS (default 'Logits'). | ||
| name: A string (optional). The name of this module. | ||
| Raises: | ||
| ValueError: if `final_endpoint` is not recognized. | ||
| """ | ||
|
|
||
| if final_endpoint not in self.VALID_ENDPOINTS: | ||
| raise ValueError('Unknown final endpoint %s' % final_endpoint) | ||
|
|
||
| super(InceptionI3d, self).__init__() | ||
| self._num_classes = num_classes | ||
| self._spatial_squeeze = spatial_squeeze | ||
| self._final_endpoint = final_endpoint | ||
| self.logits = None | ||
|
|
||
| if self._final_endpoint not in self.VALID_ENDPOINTS: | ||
| raise ValueError('Unknown final endpoint %s' % self._final_endpoint) | ||
|
|
||
| self.end_points = {} | ||
| end_point = 'Conv3d_1a_7x7' | ||
| self.end_points[end_point] = Unit3D(in_channels=in_channels, output_channels=64, kernel_shape=[7, 7, 7], | ||
| stride=(2, 2, 2), padding=(3,3,3), name=name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'MaxPool3d_2a_3x3' | ||
| self.end_points[end_point] = MaxPool3dSamePadding(kernel_size=[1, 3, 3], stride=(1, 2, 2), | ||
| padding=0) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Conv3d_2b_1x1' | ||
| self.end_points[end_point] = Unit3D(in_channels=64, output_channels=64, kernel_shape=[1, 1, 1], padding=0, | ||
| name=name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Conv3d_2c_3x3' | ||
| self.end_points[end_point] = Unit3D(in_channels=64, output_channels=192, kernel_shape=[3, 3, 3], padding=1, | ||
| name=name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'MaxPool3d_3a_3x3' | ||
| self.end_points[end_point] = MaxPool3dSamePadding(kernel_size=[1, 3, 3], stride=(1, 2, 2), | ||
| padding=0) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Mixed_3b' | ||
| self.end_points[end_point] = InceptionModule(192, [64,96,128,16,32,32], name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Mixed_3c' | ||
| self.end_points[end_point] = InceptionModule(256, [128,128,192,32,96,64], name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'MaxPool3d_4a_3x3' | ||
| self.end_points[end_point] = MaxPool3dSamePadding(kernel_size=[3, 3, 3], stride=(2, 2, 2), | ||
| padding=0) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Mixed_4b' | ||
| self.end_points[end_point] = InceptionModule(128+192+96+64, [192,96,208,16,48,64], name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Mixed_4c' | ||
| self.end_points[end_point] = InceptionModule(192+208+48+64, [160,112,224,24,64,64], name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Mixed_4d' | ||
| self.end_points[end_point] = InceptionModule(160+224+64+64, [128,128,256,24,64,64], name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Mixed_4e' | ||
| self.end_points[end_point] = InceptionModule(128+256+64+64, [112,144,288,32,64,64], name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Mixed_4f' | ||
| self.end_points[end_point] = InceptionModule(112+288+64+64, [256,160,320,32,128,128], name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'MaxPool3d_5a_2x2' | ||
| self.end_points[end_point] = MaxPool3dSamePadding(kernel_size=[2, 2, 2], stride=(2, 2, 2), | ||
| padding=0) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Mixed_5b' | ||
| self.end_points[end_point] = InceptionModule(256+320+128+128, [256,160,320,32,128,128], name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Mixed_5c' | ||
| self.end_points[end_point] = InceptionModule(256+320+128+128, [384,192,384,48,128,128], name+end_point) | ||
| if self._final_endpoint == end_point: return | ||
|
|
||
| end_point = 'Logits' | ||
| self.avg_pool = nn.AvgPool3d(kernel_size=[2, 7, 7], | ||
| stride=(1, 1, 1)) | ||
| self.dropout = nn.Dropout(dropout_keep_prob) | ||
| self.logits = Unit3D(in_channels=384+384+128+128, output_channels=self._num_classes, | ||
| kernel_shape=[1, 1, 1], | ||
| padding=0, | ||
| activation_fn=None, | ||
| use_batch_norm=False, | ||
| use_bias=True, | ||
| name='logits') | ||
|
|
||
| self.build() | ||
|
|
||
|
|
||
| def replace_logits(self, num_classes): | ||
| self._num_classes = num_classes | ||
| self.logits = Unit3D(in_channels=384+384+128+128, output_channels=self._num_classes, | ||
| kernel_shape=[1, 1, 1], | ||
| padding=0, | ||
| activation_fn=None, | ||
| use_batch_norm=False, | ||
| use_bias=True, | ||
| name='logits') | ||
|
|
||
| def build(self): | ||
| for k in self.end_points.keys(): | ||
| self.add_module(k, self.end_points[k]) | ||
|
|
||
| def forward(self, x, pretrained=False, n_tune_layers=-1): | ||
| if pretrained: | ||
| assert n_tune_layers >= 0 | ||
|
|
||
| freeze_endpoints = self.VALID_ENDPOINTS[:-n_tune_layers] | ||
| tune_endpoints = self.VALID_ENDPOINTS[-n_tune_layers:] | ||
| else: | ||
| freeze_endpoints = [] | ||
| tune_endpoints = self.VALID_ENDPOINTS | ||
|
|
||
| # backbone, no gradient part | ||
| with torch.no_grad(): | ||
| for end_point in freeze_endpoints: | ||
| if end_point in self.end_points: | ||
| x = self._modules[end_point](x) # use _modules to work with dataparallel | ||
|
|
||
| # backbone, gradient part | ||
| for end_point in tune_endpoints: | ||
| if end_point in self.end_points: | ||
| x = self._modules[end_point](x) # use _modules to work with dataparallel | ||
|
|
||
| # head | ||
| x = self.logits(self.dropout(self.avg_pool(x))) | ||
| if self._spatial_squeeze: | ||
| logits = x.squeeze(3).squeeze(3) | ||
| # logits is batch X time X classes, which is what we want to work with | ||
| return logits | ||
|
|
||
|
|
||
| def extract_features(self, x): | ||
| for end_point in self.VALID_ENDPOINTS: | ||
| if end_point in self.end_points: | ||
| x = self._modules[end_point](x) | ||
| return self.avg_pool(x) |
Oops, something went wrong.